SearchStax Managed Search service is a fully-managed hosted Solr SaaS solution that automates, manages and scales Solr infrastructure.
For a basic orientation to Solr itself, see What is Solr?
Here is a short glossary to help you understand the components of a Managed Search Solr deployment and how they provide High Availability, Fault Tolerance, and Disaster Recovery.
Note: In Solr terminology, there is a sharp distinction between the logical parts of an index (collections, shards) and the physical manifestations of those parts (cores, replicas). In this diagram, the “logical” concepts are dashed/transparent, while the “physical” items are solid.
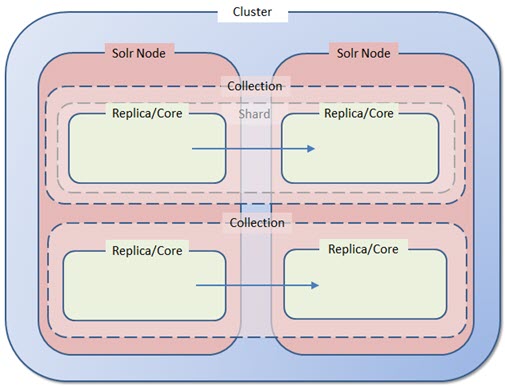
| Element | Description | |||
| Node | • In Managed Search deployments, one Solr node corresponds to one physical server. • Single-node systems are for testing and development. They do not provide the high-availability/fault-tolerant (HA/FT) behavior needed by production systems. • A single-node deployment uses an Nginx load-balancer. The log files are not available to the user. • The node hosts a single Zookeeper instance on the same server as Solr. • If Solr stops, query service stops. • A single-node system can be upgraded to increase memory, CPUs, and disk space. It cannot be expanded to create a cluster. |
|||
| Cluster | • A SearchStax “Nextgen” cluster has at least two Solr nodes to provide high-availability/fault-tolerant behavior. If a Solr issue degrades or stops one node, query traffic automatically continues on the other node(s). • A cluster has a dedicated Load Balancer. It stores a week of log files. • The cluster includes a three-node Zookeeper ensemble. The Zookeeper and Solr instances are not co-resident on the same servers. • There is no upper limit on the number of Solr nodes in a cluster. |
|||
| Zookeeper Ensemble | • Zookeeper ensures that changes to config files and updates to index segments are automatically distributed across the nodes of the cluster. • It also determines which Solr server is the “leader” node for each of the collections. |
|||
| Collection | • A “collection” is a single logical index in its entirety, regardless of how many replicas or shards it has. • One Solr node can host multiple collections. (A single Sitecore site typically generates over a dozen Solr collections.) |
|||
| Shard | • A “shard” is a logical subset of the documents in a collection. Shards let us split a massive index across multiple servers. • SearchStax clients don’t usually subdivide their collections, so for our purposes a “shard” and a “collection” are the same thing. We rarely speak of shards. • Sharding multiplies the number of servers required to achieve high-availability/fault-tolerant behavior. • Sharding greatly complicates backup and restore operations. • If your index can fit comfortably on one server, then use one shard. This is Solr’s default behavior. |
|||
| Core and Replica | • A “core” is a complete physical index on a Solr node. In a typical Managed Search deployment, a “core” is replicated to multiple nodes. Therefore, “replicas” are cores. • Due to the details of index segment processing, replicas of an index are not all the same physical size. • To achieve high-availability/fault-tolerant (HA/FT) behavior, every node of the cluster must have a replica of every collection. • When you create a collection, set replicationFactor equal to the number of nodes in the cluster. Replication is automatic after that step. • It is a SearchStax convention to speak of replicas rather than cores, hopefully avoiding confusion. |
|||
| High-Availability | • “High-availability (HA)” refers to a cluster of redundant Solr nodes, all of which can respond to queries. If one node goes down, the other nodes can temporarily take up the query load. | |||
| Fault-Tolerant | • “Fault-tolerance (FT)” enables Solr to continue to serve queries, possibly at a reduced level, rather than failing completely when a component of Solr gets into difficulty. • Solr/Zookeeper has fault-tolerant strategies such as automatically rebuilding a replica that has become unresponsive. These features handle mild issues if given enough time, but can become overwhelmed. |
|||
| Rolling Restart | • When a Solr system has been severely stressed, its fault-tolerant features can get stuck in a degraded state. There are many possible ways for this to happen, frustrating a direct link from cause to result. • The “root cause” of this situation is usually that the client sent too many /update requests in too short a time, or that the updates were inefficient. CPU and memory became overloaded, and unneeded subsystems were shut down (but were not automatically restarted). • A “rolling restart” shuts down each Solr node in the cluster and restarts it. This returns Solr to a known state. Due to the cluster’s High Availability, this does not interrupt query service. • SearchStax provides a button on the Deployment Details screen to let you do a rolling restart at any time. |
|||
| Disaster Recovery | • Disaster Recovery refers to:
• DR failover occurs automatically when High-Availability fails (all nodes have been unresponsive for five minutes ). |
Questions?
Do not hesitate to contact the SearchStax Support Desk.