SearchStax Managed Search service clients sometimes complain that a collection has stopped responding during batch ingestion of new documents. Frequently, the root problem is too-frequent attempts to “commit” the new documents to the index.
Solr supports rapid indexing by temporarily accumulating the new index records in memory. This is very fast, but the new records are not searchable and have not been “persisted” to permanent storage.
A commit (sometimes called a “hard commit”) flushes the new records to index files on disk. The commit also initializes a new Searcher to make the new items available to queries. This sounds very attractive to new Solr users, who sometimes demand a commit after every update (commit=true) or within a second of every update (commitWithin=1000).
Unfortunately, the commit process is expensive. Ingestion waits while Solr writes records to disk. Then Zookeeper distributes the updated files to the appropriate replicas across the cluster. Once distributed, the updates then undergo merging with previous index files.
If commit requests are too frequent, the system bogs down in file operations, replication, and sorting. The CPU gets overloaded. Zookeeper gets far enough behind to trigger recovery mode for some of the replicas. Everything grinds to a halt.
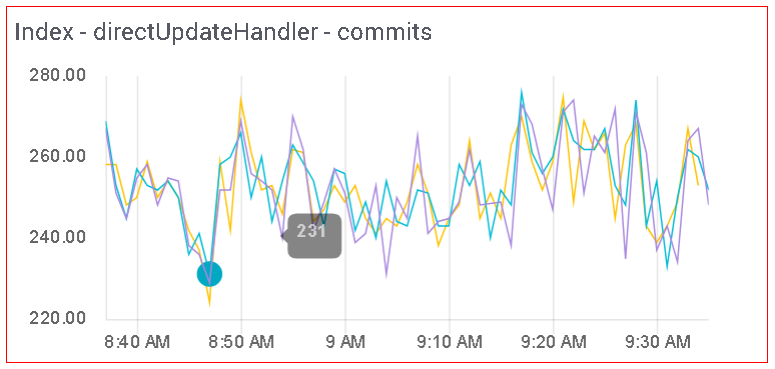
For instance, the system shown above is running 250 commits per minute (four per second)! This slows down the acquisition of new documents rather than speeding it up.
Experience (and common sense) tell us that very few Solr systems need to provide sub-second updates during bulk uploads of thousands of records. By default, Solr autoCommits every 15 seconds. This is usually sufficient to persist the new records, distribute them among replicas, and keep search results fresh.
There is an exception. Sitecore sometimes sends multiple commit requests per second. One way to shield Solr from these commands is to invoke the IgnoreCommitOptimizeUpdateProcessorFactory. This is a Solr update stage that removes commit=true, commitWithin, and Optimize commands from incoming /update requests. The payload documents are processed as usual, but commits are performed every few minutes (adjustable as you see fit). We have provided simple step-by-step instructions.
Questions?
Do not hesitate to contact the SearchStax Support Desk.