Account Owner, Admin, or Technical Contact
To perform backup/restore operations in the SearchStax Managed Search service, you must be the account Owner, an account Admin, or a Technical Contact. See SearchStax User Roles.
A SearchStax Managed Search service “backup” is a copy of the deployment’s configuration files, index files, and any .JAR files that are needed. Any condition that interferes with copying these files can produce a backup failure. Some of these events are temporary and will correct themselves. Some can be cleared by the user or by support. Some mean that you have outgrown your deployment and need to upgrade.
A backup requires plentiful free disk space!
For successful backups, we recommend that your deployment’s disk space be three times the size of your index. As the index approaches half of the disk space, backups fail. The exact limit depends on the deployment. See How much free disk space do I have?
After the backup is complete, Managed Search automatically moves the backup file to blob storage. This frees up space for making your next backup.
Automatic Retry of Failed Backup
When a scheduled backup of a premium deployment fails:
- Managed Search automatically sends email to every registered member of that account.
- Since many backup problems can clear themselves after a brief time (see below), the system waits two hours and attempts the backup again.
- If the backup fails a second time, another email is sent to your team. The system also alerts our technical-operations team at that time.
Common reasons for Solr backup failure include:
- Could not connect to Solr for collection <collection-name>. You may receive an email from Managed Search containing this message. It means one of these things:
- Solr was too busy to perform the backup. See the entries below for reasons this can happen.
- A hard commit occurred during the backup. See the entries below relating to commit frequency.
- The backup took more than one hour to complete. Contact SearchStax Support to investigate.
- Creating a backup temporarily doubles the disk space devoted to index files. If the deployment runs out of disk space, the backup fails.
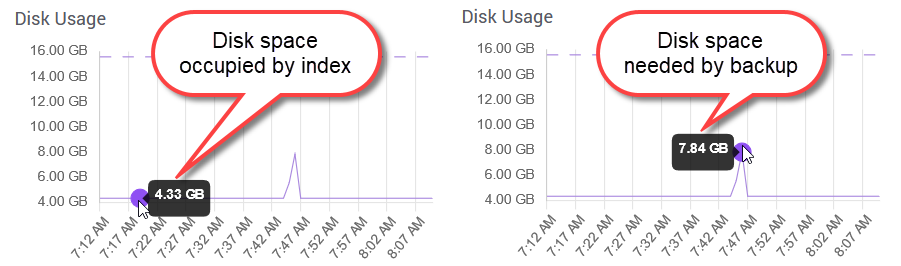
Remedies include:- Clean up your deployment by deleting unneeded collections and configs.
- Purchase additional disk space. Contact SearchStax Support.
- Upgrade to a larger deployment.
- A spike in System Load Average can sometimes leave the snapshot creation process in an inconsistent state. Backups rely heavily on this process. Subsequent backups fail intermittently. Remedy: Contact SearchStax Support so we can restart it for you.
- It is possible for the lead node of a cluster to have larger index segment files than the non-lead node(s). This sometimes results in intermittent backup failure due to one node having less free disk space than the other(s). Remedy: Contact SearchStax Support.
- Managed Search cannot back up a Solr node that isn’t running. Remedy: Restart Solr and try again.
- Managed Search cannot make a copy of a replica that is in recovery mode. Remedy: Wait until the replica comes back on line.
- Backup fails when the replicas of a collection are not evenly distributed across all nodes. Remedy: Adjust the Replication Factor of the collection.
- Managed Search cannot back up a “ghost” replica created by downsizing the cluster. Remedy: Manually delete the ghost.
- Managed Search cannot back up a sharded index. Remedies:
- Reconfigure the collection to use a single shard.
- Core and Enterprise clients can contact SearchStax Support about filing a Support Request for a customize backup solution.
- Commit rate is too high. See Timeouts during ingestion: Too many commits! Remedies:
- Modify solrconfig.xml to lower commit rates. See 5 Ways to Optimize Solr Search Performance for Sitecore.
- Lower the commit rate for Sitecore XBD collection updates. See Performance optimization for the xConnect Search Service when using Solr.
- Zookeeper is corrupt. Contact SearchStax Support so we can restart it for you.
- Solr is low on resources. Remedies:
- Wait until the spike in demand has passed.
- Do a rolling restart of your Solr nodes.
- Zookeeper is low on resources.
- Wait until the spike in demand has passed.
- Contact SearchStax Support so we can restart Zookeeper for you.
Questions?
Do not hesitate to contact the SearchStax Support Desk.