SearchStax Managed Search service clients sometimes notify us that a slow or unresponsive system shows this error message in the solr.log files:
WARN false
x:a01cbk_cb_custom_web_index_rebuild_shard1_replica_n2
DistributedZkUpdateProcessor
Error sending update to http://10.33.45.4:8983/solr
org.apache.solr.client.solrj.SolrServerException: Max requests queued per destination 3000 exceeded for HttpDestination[http://10.33.45.4:8983]@4c54160b,queue=3000,pool=MultiplexConnectionPool@4293f1f1[c=0/4/4,a=0,i=0]
The clients then ask how to increase the size of the Zookeeper request queue.
Systems showing this message are usually misconfigured. Overloaded results in cascading failures of CPU, load, memory, and replica recovery issues. The final step in this cascade occurs when Zookeeper has many updates to send to a replica that is in recovery. Zookeeper stashes these updates in a request queue. When this queue fills up, we see the warning message shown above.
Configuration Changes
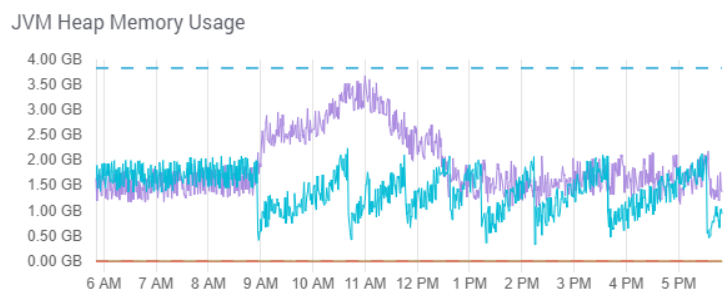
The graphs below were all taken from an actual Managed Search deployment that reported “requests queued per destination 3000 exceeded.”
For most applications, a Solr “commit” every few minutes is sufficient. In overloaded systems, we often see hundreds of commits per minute. This maximizes CPU, disk, and network activity causing replicas to go into recovery mode. See Taming Commits.
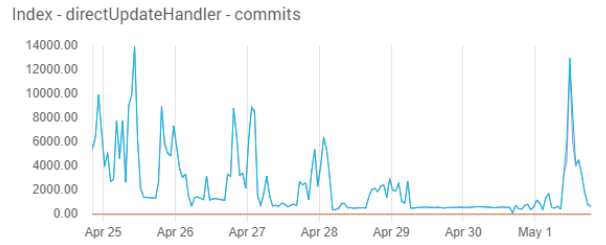
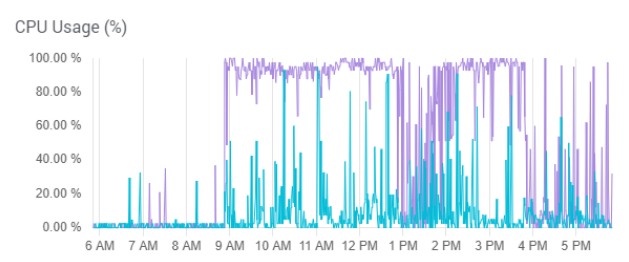
High commit rate (and high CPU) are usually caused by a heavy stream of /update requests that include a commit=true or commit-within=1000 notation.
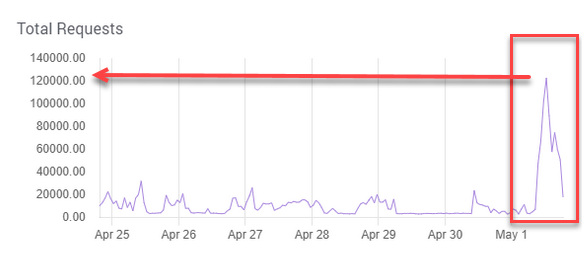
The updates themselves fill up JVM as Solr tries to process them in parallel. You can see this in the system load graph and JVM graph.
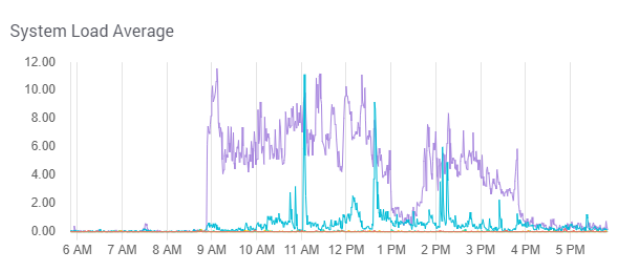
The system in question could handle a maximum load of 2, but heavy indexing forced the backlog into the 6-to-12 range.
When users send queries to Solr, they rarely expect more than 100 or 1000 matching documents. In overloaded systems, we see thousands of queries that each allocate memory for a million documents, eating up memory. See Lowering &rows=1000000.
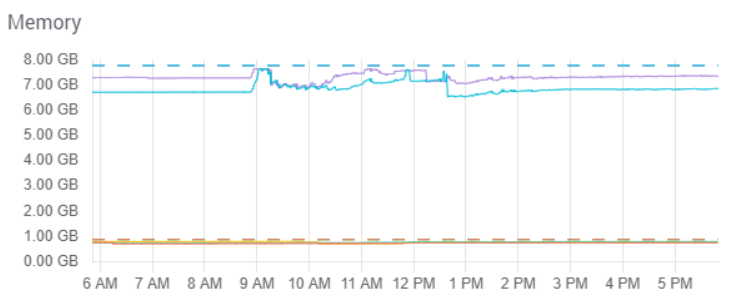
So the “requests queued per destination 3000 exceeded” message implies a need for configuration adjustments that throttle updates and queries, and make them run more efficiently.
Remedial Treatment
The remedy to the immediate crisis is to do a “rolling restart” on the cluster. A restart clears the overloaded memory and forces Solr to repair the indexes from transaction logs. Experience shows this is the fastest route to system recovery.
If all nodes and replicas are on-line, you can do a rolling restart yourself. See Restart SearchStax Managed Search Deployments. If the system has begun to fail, you’ll have to ask the SearchStax Support Desk for assistance.
Questions?
Do not hesitate to contact the SearchStax Support Desk.