SearchStax Managed Search service users sometimes ask us how to export a large Solr collection to a reloadable file. The Solr “cursor” feature is the right tool for this job.
Performance Problems with Deep Paging
Dumping the entire contents of a Solr collection is more challenging than you might think. This is a passage from the Solr 8.10 documentation:
When you wish to fetch a very large number of sorted results from Solr to feed into an external system, using very large values for the start or rows parameters can be very inefficient. Pagination using start and rows not only require Solr to compute (and sort) in memory all of the matching documents that should be fetched for the current page, but also all of the documents that would have appeared on previous pages.
While a request for start=0&rows=1000000 may be obviously inefficient because it requires Solr to maintain & sort in memory a set of 1 million documents, likewise a request for start=999000&rows=1000 is equally inefficient for the same reasons. Solr can’t compute which matching document is the 999001st result in sorted order, without first determining what the first 999000 matching sorted results are.
If the index is distributed, which is common when running in SolrCloud mode, then 1 million documents are retrieved from each shard. For a ten shard index, ten million entries must be retrieved and sorted to figure out the 1000 documents that match those query parameters.
Fortunately, Solr provides cursors that let us create scripts to iterate through a collection and capture all of the documents efficiently. There is also a shared script here on Github.
Cursor Example
The following example will familiarize you with the Solr cursor mechanism. You will then have to write a script that issues Solr /select queries and captures the search results.
Go to your Solr Dashboard. Select a collection and open the Query page. Set up the first query like this one:
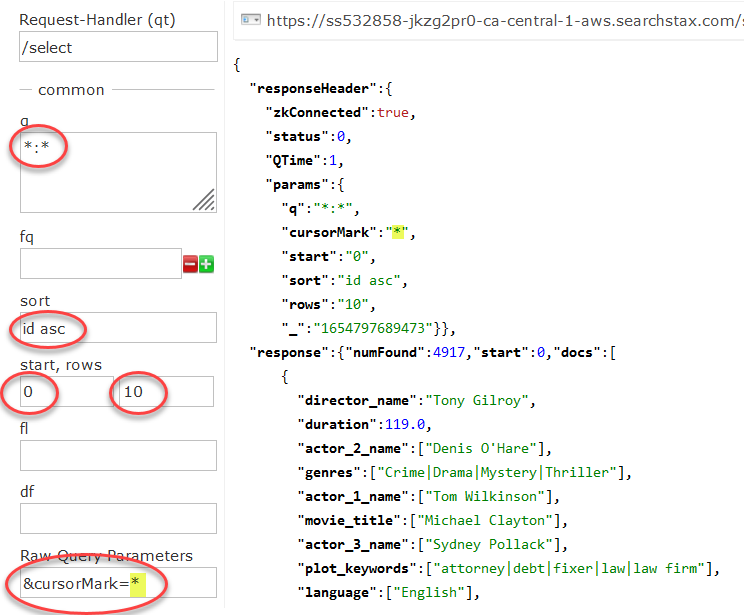
The cursor mechanism requires that the query results be sorted by a unique field (the id field in this case). Ask for an ascending sort (asc).
Set the start and rows parameters to indicate how large a block of results you want from each iteration of your query. Values of 0 and 10 are sufficient for this exercise.
Under Raw Query Parameters enter &cursorMark=*. The asterisk directs Solr to the beginning of the sorted list of document ids.
Click the Execute Query button. Examine the Response document (included in the image above).
Now scroll down to the very last line in the Response document.

The nextCursorMark is a bookmark pointing to the final document id that was returned by the search. Using it, we can launch another search that begins where the previous search ended.
Copy the nextCursorMark value and paste it into the Raw Query Parameters as the value of the cursorMark parameter.
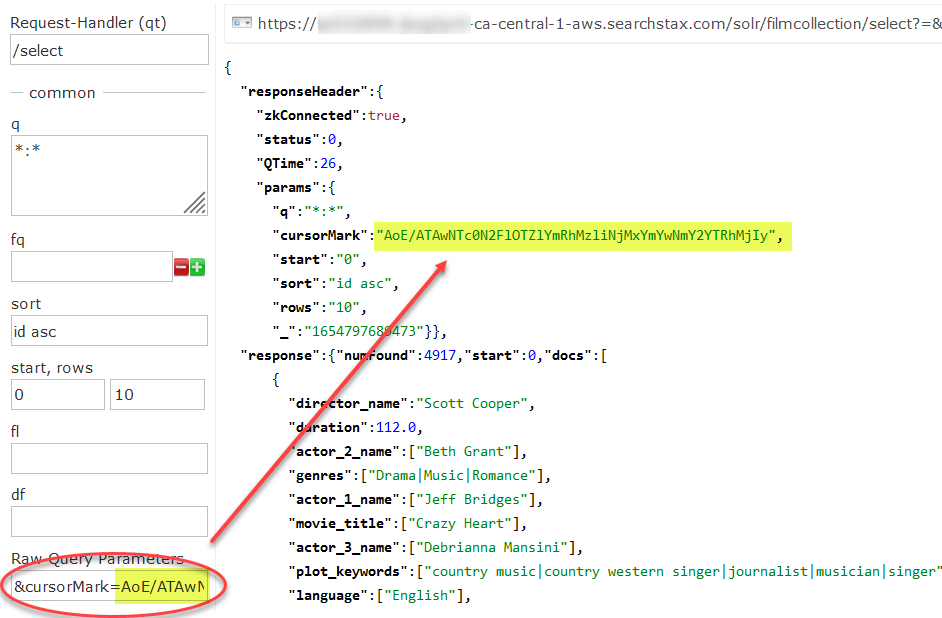
This query gives us the next ten documents (or the number you asked for with &rows). At the bottom of the Response document is the new nextCursorMark for the next iteration.
Rinse and repeat.
When you reach the end of the documents, Solr will stop incrementing nextCursorMark. When Solr hands you the same value twice in a row, you are finished. It is up to your script to excise the documents from the output and write a file.
Questions?
Do not hesitate to contact the SearchStax Support Desk.