The Crawler History Tab sometimes says that the Crawler indexed more pages than it crawled. What does this mean?
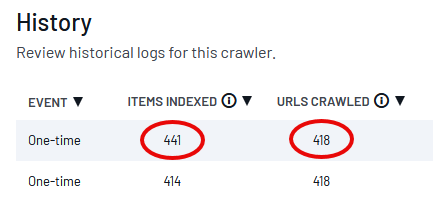
This puzzling result sometimes appears when the workload was distributed across multiple parser processes. One of the processes failed before reporting which files it had indexed successfully.
Another process then picked up the task and reindexed a few of the files. This behavior is harmless.
Since the index records are identified by webpage URL, deduplication is automatic. No action is required.
Questions?
Do not hesitate to contact the SearchStax Support Desk.