The SearchStax Site Search solution and the Managed Search solution both honor the search industry’s use of stemming to help focus website search results. Stemming increases the chances of retrieving all relevant documents by treating word variations as equivalent.
For instance, a typical stemmer would convert the words running, runs, and ran to the stem run. A query for “running” would match documents using “ran,” among others.
Stemming is a complex topic with a fifty-year history of research and development. Solr uses a variety of stemmers to best match text in multiple languages. SearchStax users have no direct input on stemming behavior through our products.
Solr Stemming Factories
Managed Search and Site Search apply appropriate stemming algorithms to text-based index fields. These algorithms are implemented as “factories” that apply language-specific stemming.
PorterStemFilterFactory
Solr’s Porter Stem Filter implements the Porter Stemming Algorithm, the industry standard for stemming English text.
The stemmers are configured in the fieldType definitions in the Solr managed-schema file. This is the definition for the text_en field.
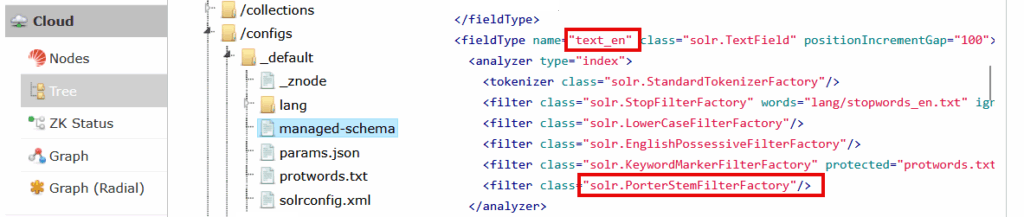
In Site Search, both Custom and Sitecore apps use Porter on the text_en field.
Snowball Porter Filter Factory
The Snowball variants on the Porter stemming factory handle non-English stemming. Solr offers Snowball stemmers for Armenian, Basque, Catalan, Danish, Dutch, English, Finnish, French, German, Hungarian, Italian, Norwegian, Portuguese, Romanian, Russian, Spanish, Swedish, and Turkish.
In Site Search, Drupal apps apply Snowball to text_en fields.
Questions?
Do not hesitate to contact the SearchStax Support Desk.