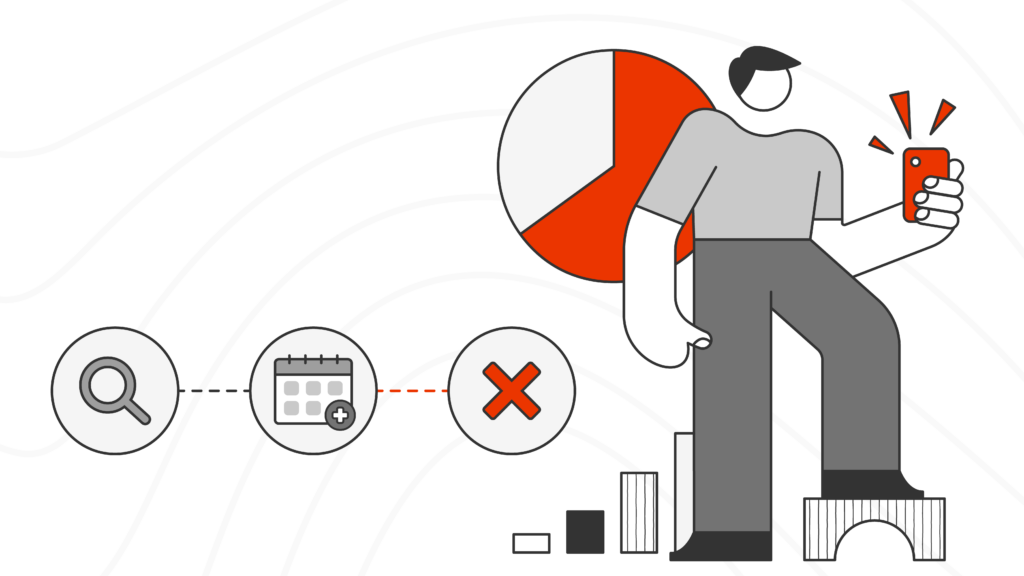
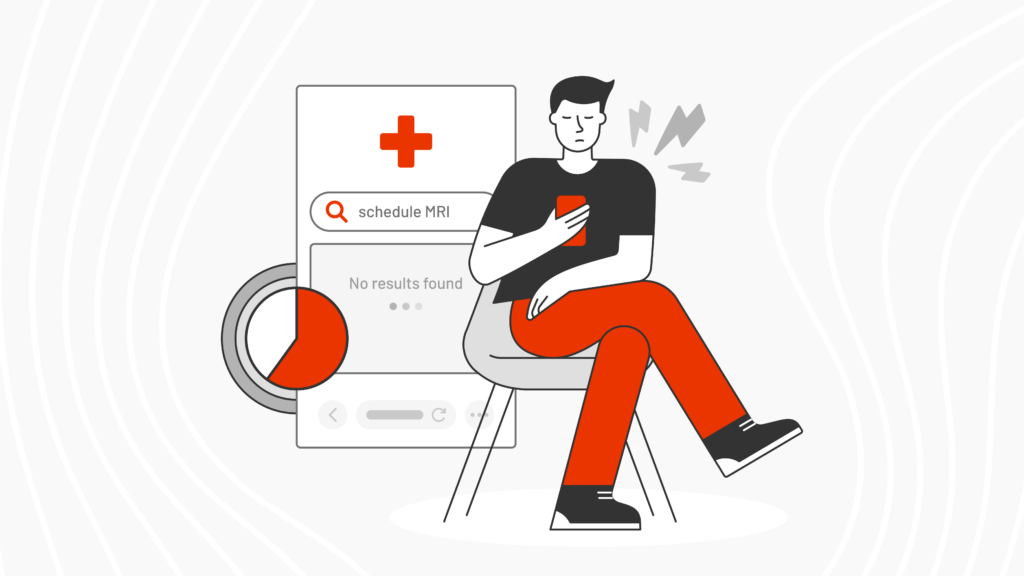
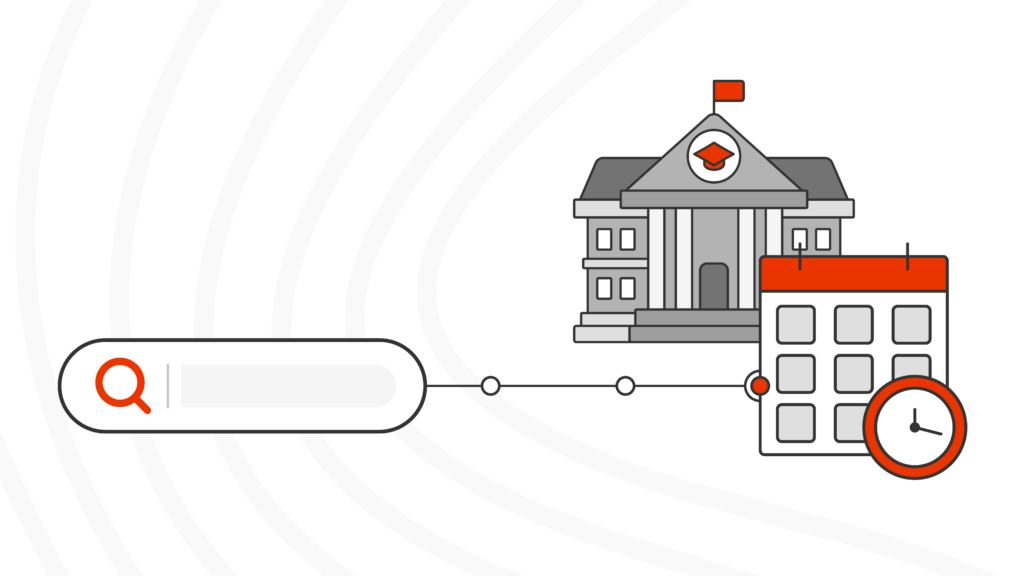
Almost 3/4 of higher ed marketing teams publish content weekly or ad hoc, but 43% say it takes a week or more to make that content findable via onsite search.
What Does Solr 10 Change for Enterprise AI Retrieval?
Solr 10 gives enterprise search teams stronger vector retrieval controls for RAG, copilots and agent workflows. See how Managed Search supports Solr...
Solr 10 gives enterprise search teams stronger vector retrieval controls for RAG, copilots and agent…