Introduction to Importing Data into Apache Solr
Importing your data into our Solr-as-a-Service offering might seem like a daunting task, but Solr provides a lot of out-of-the box tools to help you do that. Depending upon the amount and type of data being imported, we can decide which tool might best fit your need. Apache Solr lets you choose the tool that you might want to use to, say, insert only one document, or insert data directly from your application, or maybe you want Solr to get data directly from your database, or you might want to upload binary files and extract data from it, or use a web crawler to feed data to Solr and index it directly. Regardless of your use case, there’s a way to import data into Apache Solr.
All of these different scenarios warrant a blog post of their own but in this tutorial, we will take a high level look at importing data into Solr and then we’ll follow up with a couple of specific posts regarding MongoDB and PostgreSQL databases and what are the best ways to do it.
Tools to Import Data into Solr
Apache Solr famously supports the following tools to import data –
- Update handler
- SolrJ
- Data Import Handler
- Solr Cell
- Nutch
Update handler lets you POST data into a collection using the update API. This API lets you insert, update, and delete documents and can either be called programmatically, or via terminal.
SolrJ is a client library that lets your application communicate with the Solr deployment easily. SolrJ is available for Java, .NET, Ruby, Python, and PHP.
Data Import Handler is an extension that pulls data directly from a database. It can interact with multiple databases and query them to get data for your collection.
Solr Cell allows you to index the text-based content of binary files. This can be used to index PDF, MS Office, and Open office documents.
Nutch is a web crawler by Apache that can help you get the content of webpages and make it searchable using Solr.
Data Import Handler
Data Import Handler (DIH) is an extension that lets Apache Solr query the data source directly and import data from it. It can be configured to get data from multiple databases, flat files, or can even be configured to get data from websites. DIH also provides the capability of performing a delta import, i.e. once the database has been queried and full-import has finished, it can be configured to import delta on regular intervals. Which means that you don’t need to write a program to keep your Solr data up to date.
DIH works with all the databases that provide JDBC drivers, such as MySQL, MS SQL Server, Oracle, or PostgreSQL with minimal configuration. In case of databases that do not provide JDBC drivers, like MongoDB, we can configure DIH to use custom connectivity and transformation drivers to get data and transform it.
Configuring Data Import Handler
Using DIH requires following important configuration items:
| solrconfig.xml | Create an API for DataImportHandler; Configure solr to read custom JARs related to JDBC drivers |
|---|---|
| data-config.xml | JDBC connection string; Import query; Delta query |
| Schema.xml / managed-schema | Configure the schema to let Solr recognize the incoming data |
| contrib/dataimporthandler/lib | connectivity drivers |
Instructions specific to certain database tools can be found here:
Using Data Import Handler
Once you have configured the DIH, then we can use the Solr UI to initiate it and start the data import.
1.Navigate to your Solr UI
2. From the menu on the left, click on the drop-down and select the appropriate collection for which you have set up the data import handler.
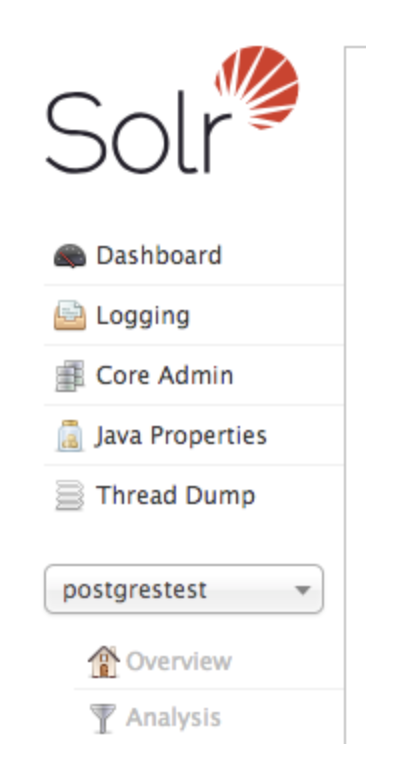
3. Go to DataImport tab.
4. Click on the (+) symbol next to Configuration to view your config file. The contents from data-config.xml will appear here.
5. You will have options to either do a full-import, or a delta-import. Select the appropriate action based on your use case.
6. In the Entity drop down menu, select the item that you defined in the data-config.xml file.
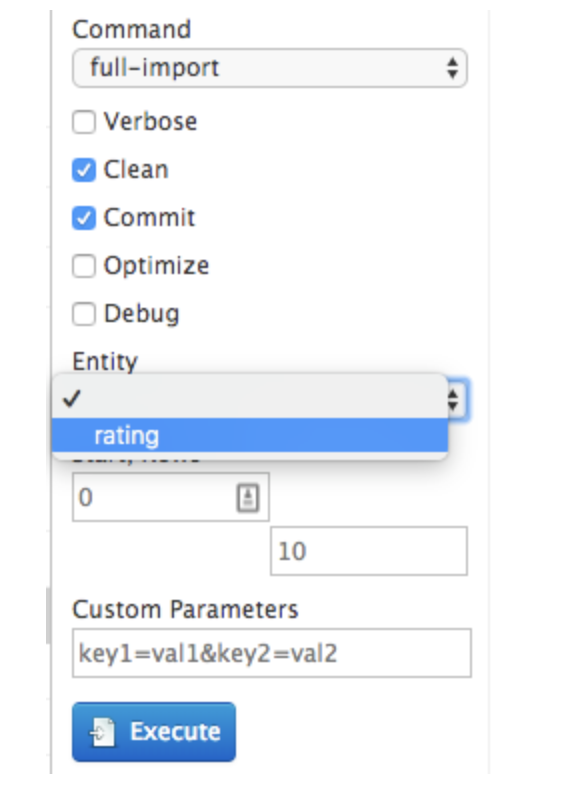
7. Click Execute.
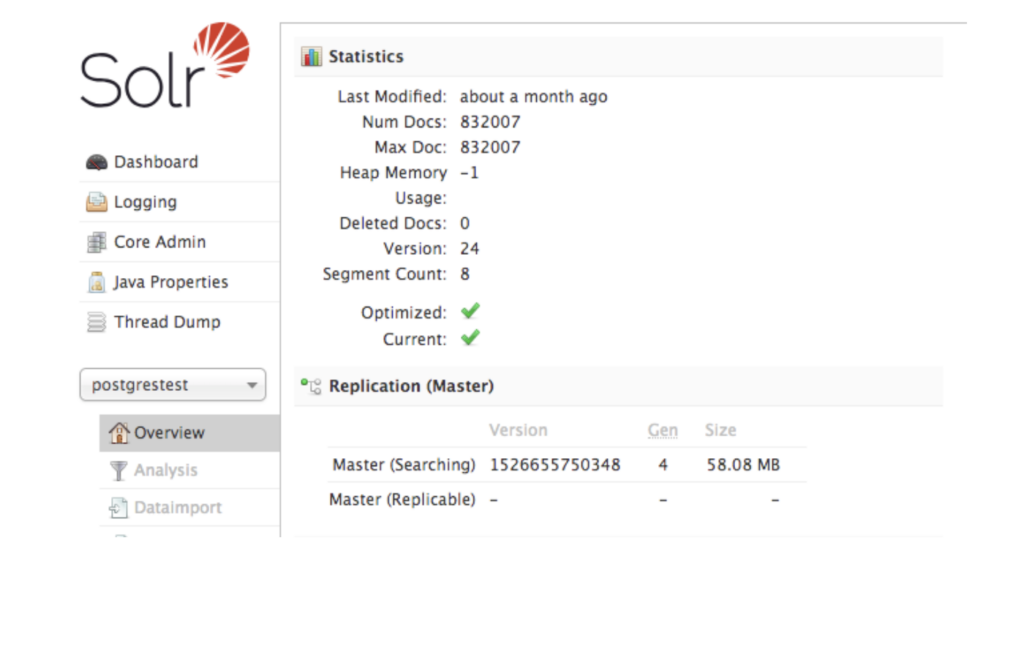
8. Once the import is finished, the doc count will be reflected in the Overview tab of your collection.
Simplify Your Other Solr-Related Tasks
Our engineers helped our clients import data from different sources into Apache Solr. Reach out to learn more about our hosted Solr solution and support.

Get Our Newsletter
The Stack is delivered bi-monthly with industry trends, insights, products and more
Karan is a scrappy Solutions guy focused on solving onboarding challenges and easing the product adoption challenges for customers.